Is it more efficient to learn by PUNISHMENT or by REWARD?
In this entry we will only talk about the results related to Machine Learning or Artificial Intelligence (AI), which are gaining more fame and usefulness every day, in any area of daily life.
There are AIs of all kinds: some learn everything from scratch, others, however, need to know what the expected results are... How would you teach these algorithms? What is more useful for learning, punishments or rewards?

Post content:
Introduction: Punishment or Reward
Some time ago I saw a video of Vsauce2 where they talked about a board game (Hexapawn) in which you yourself play against a decision tree that chooses random variants, and every time you win, you eliminate the last move from that tree. (https://youtu.be/sw7UAZNgGg8)
Little by little you will see how it is increasingly difficult to win and there will come a point where you will lose one hundred percent of the games. It is a super simple and visual example of how Artificial Intelligence works. who learn by reinforcement.
Kevin Lieber, the main face of the channel, also mentions that just as you can eliminate a bad variant every time "the machine" loses, you can also do the opposite, and add duplicates of that variant every time it wins. I found the assessment he made very interesting:
«Eliminating the variants where the machine loses is equivalent to punishment learning, and will be a very fast way to obtain almost perfect performance, while doubling the variants where it wins is often called reward learning, and although it is not such a way direct from obtaining optimal performance, the machine will be able to win many more games while it learns.
So, being as curious as I am, and knowing how to program, I started searching the internet for graphs and data so I wouldn't have to make the effort to make my own. In the end I didn't find anything and I had to move on to the second part of being a programmer: generating code for problems that are not solved on the internet. The data I have obtained is quite interesting., and I have taken the trouble to convert everything to very simple and visual graphs:
Learning by Punishment or Reward?
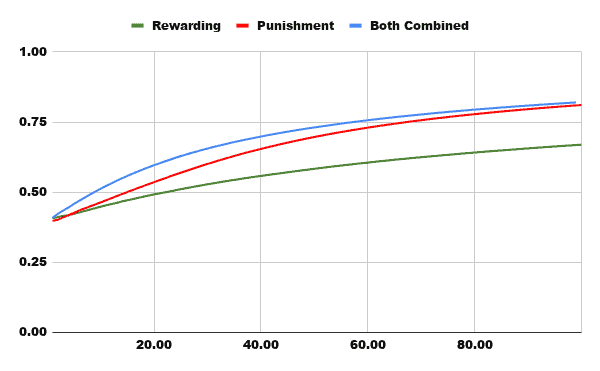
This first graph is the most representative, and shows the percentage (about 1) of games won in the first hundred games, where we see how the performance of Rewards is quite weak, the one Punishment grows considerably fast and that of Both Combined It starts out being efficient but is soon caught up with the red line.
This has an easy explanation:
(In the following graphs the value R2 will be how accurately the trend line can predict the results)
Learn by Rewards
The algorithm that learns by Reward only benefits from victories, and even then all you get is a slight increase in the probability of winning with that variant. (At first you will have a 50% probability of losing, then a 33%, a 25%, a 20%, etc…)
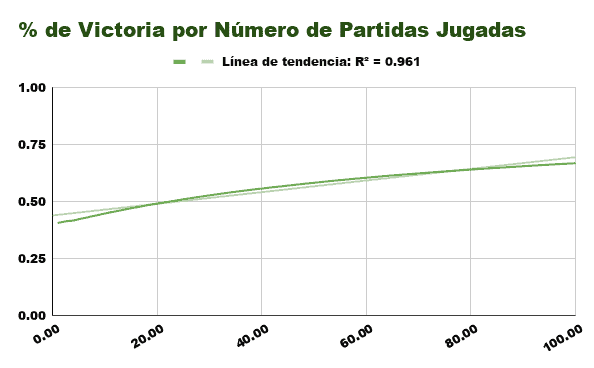
It can be seen that it does not take more than 20 games to exceed the 50% threshold of victories, but in the next 80 only 20% improves your probability of winning.
Learn by Punishments
However, when we move on to observe the behavior of the algorithm that learns by Punishment We see how it immediately obtains great performance, because the games you win add to your victories while the games you lose ensure you win more frequently the next time.
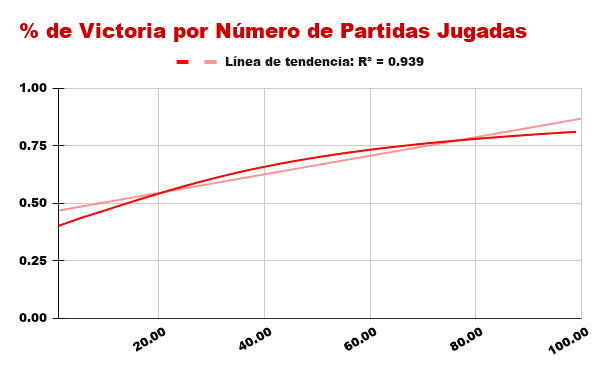
While the algorithm Reward little by little he increased his probability of victory until he reached almost 100% of good decisions, the algorithm of Punishment It directly eliminates the variants with which you have lost, thus ensuring a large and immediate increase in your future chances of victory.
Combination of both
In the case of an algorithm that combines both methods, we have already been able to verify in the comparative graph that it has a very favorable performance even up to the first 100 games, however, around that figure, the Punishment begins to be superior.
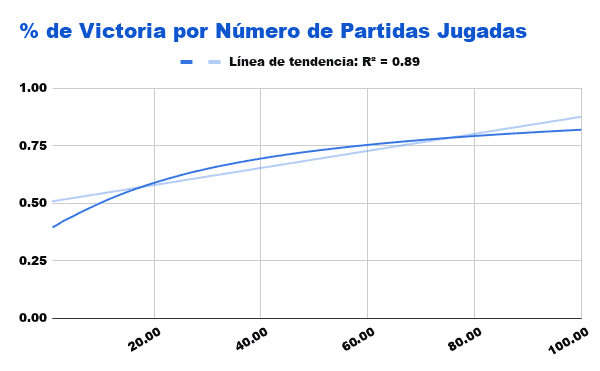
It is not surprising either, since this algorithm, When you win, you increase your chances of winning the next games, and when you lose, you directly eliminate the chances of losing with those variants again.. It seems perfect on both sides, however, As long as you don't lose with all the variants in which you can lose, you will continue to contain those possibilities, and the fact that winning games more often leads you down paths where you win won't help us in the long run. That is the reason why around one hundred games played begins to be lower than our algorithm red.
Performance and Efficiency
Average figures after 10,000 simulations:
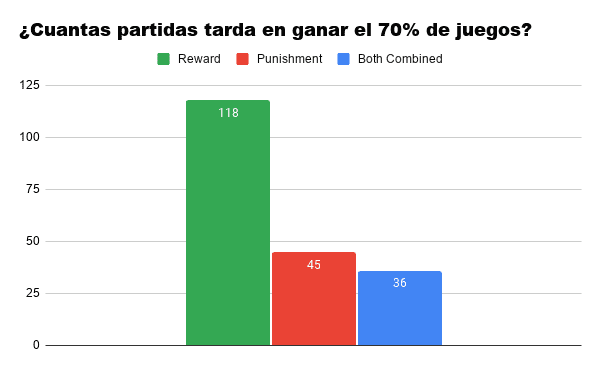
As expected, the algorithm that combines both has great performance at early "ages", reaching the performance of the 70% in just 36 games, on average, while that of Reward It takes him a lot longer to establish himself as a "good player."
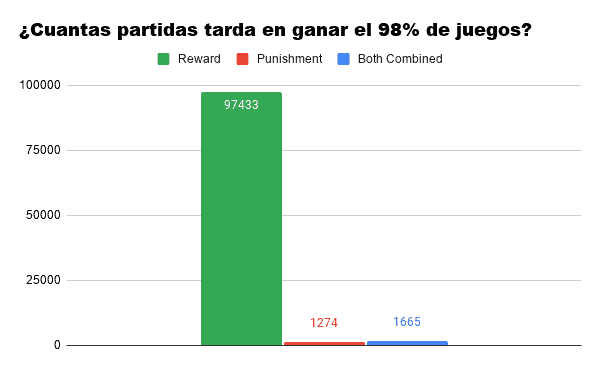
If we talk about how long it takes each algorithm to reach the average performance of the 98%, the graph skyrockets. We find that our algorithm Reward He has serious difficulties in reaching the threshold, and this is because with each victory, he learns less than with the previous one. (A variant that initially has a 50% probability of winning will later have a 66%, then a 75%, 80%, 83%, 85%, etc…)
As for the other two algorithms: here we can already see how the Punishment It takes about 400 games less than the combination of both to reach an almost perfect threshold. Even so, simulating 400 games of this mini-game is almost instantaneous and it may be that for certain functions the blue may be more practical.
Conclusion Punishment vs Reward:
I don't understand in which cases it would be convenient to use Rewards (sorry, I don't know too much about Machine Learning) but we can see that in this type of training the most convenient thing is to eliminate the negative behaviors as soon as possible since we are interested in finishing the learning phase as quickly as possible and then moving on to use the behaviors. remaining positives.
You can find the code Java of this algorithm in my public GitHub repository: https://github.com/ZaneDario/Hexapawn_Punishment_vs_Reward
