¿Es más eficiente aprender por CASTIGO o por RECOMPENSA?
En esta entrada solo hablaremos de los resultados relacionados con el Machine Learning o Inteligencias Artificiales (IA), que cada día ganan más fama y utilidad, en cualquier ámbito de la vida cotidiana.
Existen IAs de todo tipo: algunas aprenden todo desde cero, otras, en cambio, necesitan saber cuáles son los resultados esperados… ¿Cómo enseñarías a estos algoritmos? ¿Qué es más útil para aprender, castigos o recompensas?

Introducción: Castigo o Recompesa
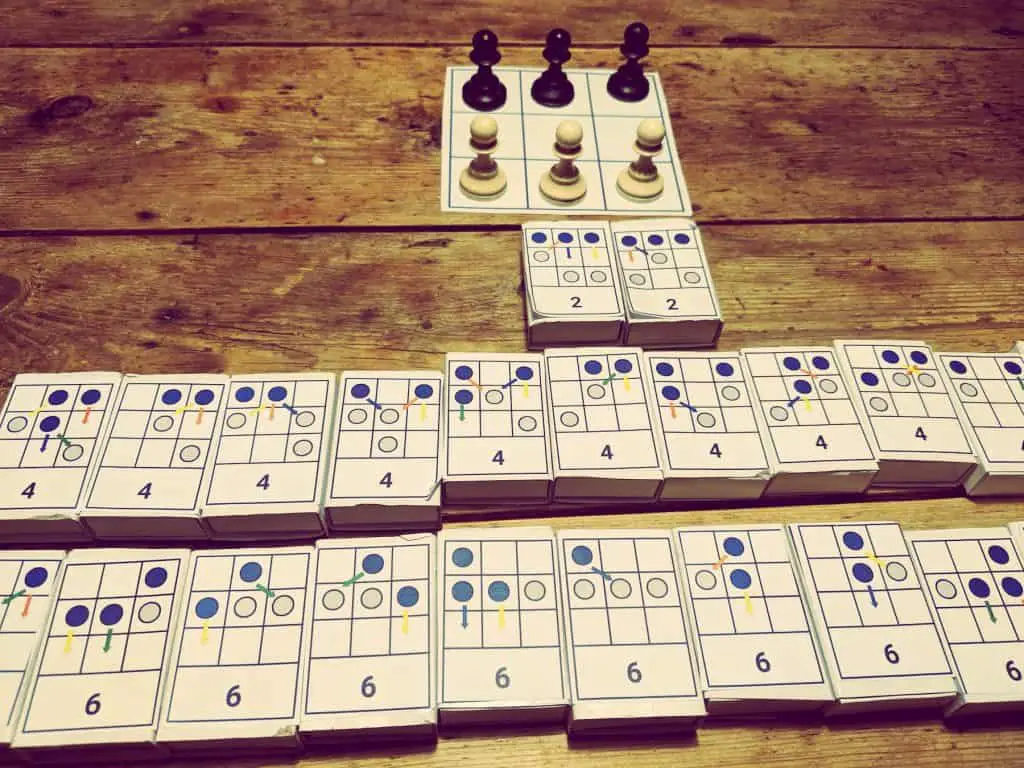
Hace ya tiempo vi un vídeo de Vsauce2 en donde hablaban sobre un juego de mesa (Hexapawn) en el que tú mismo juegas contra un árbol de decisiones que escoge variantes aleatorias, y cada vez que ganas, eliminas la última jugada de ese árbol. (https://youtu.be/sw7UAZNgGg8)
Poco a poco irás viendo como cada vez es más difícil ganar y llegará un punto en el que perderás el cien por cien de las partidas. Es un ejemplo súper sencillo y visual sobre el funcionamiento de las Inteligencias Artificiales que aprenden por refuerzo.
Kevin Lieber, la cara principal del canal, también menciona que del mismo modo que puedes eliminar una variante mala cada vez que «la máquina» pierde, puedes también hacer lo contrario, y añadirle duplicados de esa variante cada vez que gane. Me pareció muy interesante la apreciación que él hizo:
«Eliminar las variantes donde la máquina pierde equivale a aprendizaje por castigo, y será una manera muy rápida de obtener un rendimiento casi perfecto, mientras que duplicar las variantes en la que gana se suele denominar aprendizaje por recompensa, y aunque no es una manera tan directa de obtener un rendimiento óptimo, la máquina logrará ganar muchas más partidas mientras aprende».
Así que siendo tan curioso como soy, y sabiendo programar, me puse a buscar por internet gráficas y datos para no tener que esforzarme en hacer los míos. Al final no encontré nada y tuve que pasar a la segunda parte de ser programador: generar código para los problemas que no están solucionados en internet. Los datos que he obtenido son bastante interesantes, y me he tomado las molestias de convertir todo a gráficas muy simples y visuales:
¿Aprendizaje por Castigo o Recompensa?
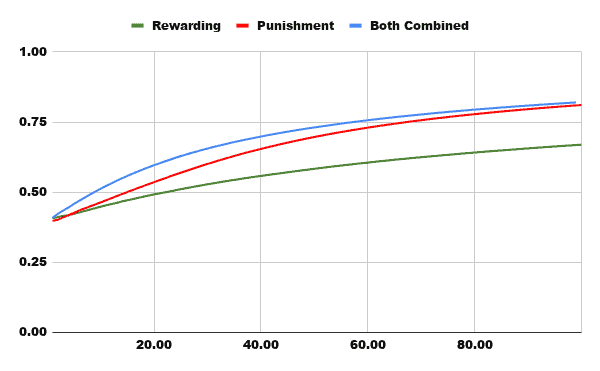
Esta primera gráfica es la más representativa, y muestra el porcentaje (sobre 1) de partidas ganadas en las primeras cien partidas, donde vemos cómo el rendimiento de Recompensas es bastante flojo, el de Castigo crece considerablemente rápido y el de Ambos Combinados empieza siendo eficiente pero enseguida es alcanzado por la línea roja.
Esto tiene fácil explicación:
(En las siguientes gráficas el valor R2 será la precisión con la que la línea de tendencia puede predecir los resultados)
Aprender por Recompensas
El algoritmo que aprende por Recompensa solo se ve beneficiado de las victorias, y aún así lo único que consigue es un leve aumento de la probabilidad de ganar con esa variante. (Al principio tendrá un 50% de probabilidades de perder, luego un 33%, un 25%, un 20%, etc…)
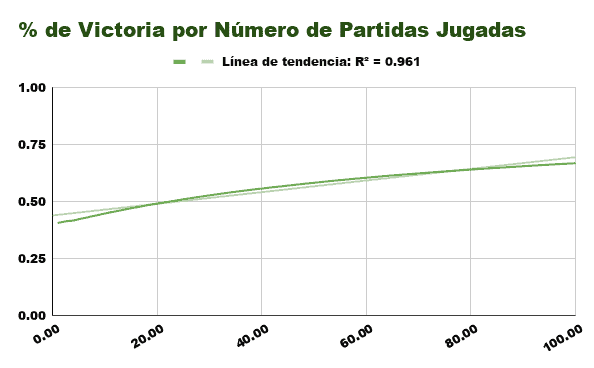
Se puede apreciar que no tarda mas que 20 partidas en superar el umbral del 50% de victorias, pero en las próximas 80 tan solo mejora un 20% su probabilidad de ganar.
Aprender por Castigos
Sin embargo, cuando pasamos a observar el comportamiento del algoritmo que aprende por Castigo observamos cómo enseguida obtiene un gran rendimiento, pues las partidas que gana le suman victorias mientras que las partidas que pierde le aseguran ganar más frecuentemente la próxima vez.
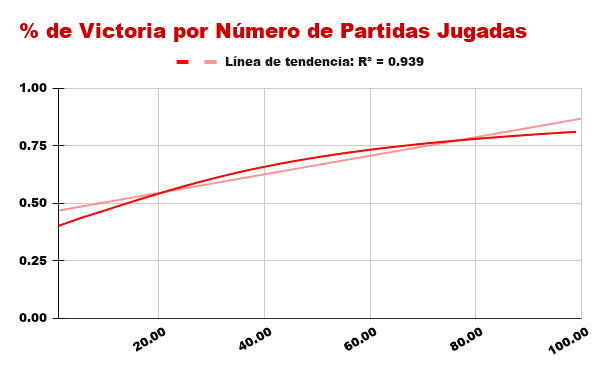
Mientras que el algoritmo de Recompensa poco a poco incrementaba su probabilidad de victoria hasta alcanzar casi el 100% de buenas decisiones, el algortimo de Castigo directamente elimina las variantes con las que ha perdido, asegurándose así un aumento grande e inmediato de sus futuras probabilidades de victoria.
Combinación de Ambos
En el caso de un algoritmo que combine ambos métodos, ya hemos podido comprobar en la gráfica comparativa que tiene un rendimiento muy favorable incluso hasta las 100 primeras partidas, sin embargo, entorno a esa cifra, el de Castigo comienza a ser superior.
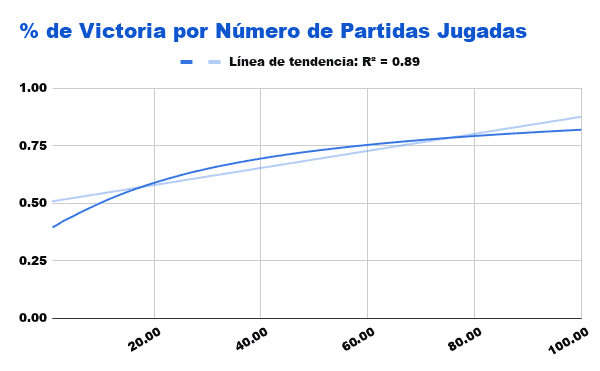
Tampoco es de extrañar, pues este algoritmo, cuando gana, aumenta sus probabilidades de ganar las próximas partidas, y cuando pierde, directamente elimina las posibilidades de perder con esas variantes de nuevo. Parece perfecto por ambos lados, sin embargo, mientras no pierda con todas las variantes en las que puede perder, seguirá conteniendo esas posibilidades, y el hecho de que ganar partidas le conduzca más frecuentemente por caminos en los que gana no nos ayudará a la larga. Esa es la razón por la que entorno a las cien partidas jugadas comienza a ser inferior a nuestro algoritmo rojo.
Rendimiento y Eficacia
Cifras promedio después de 10.000 simulaciones:
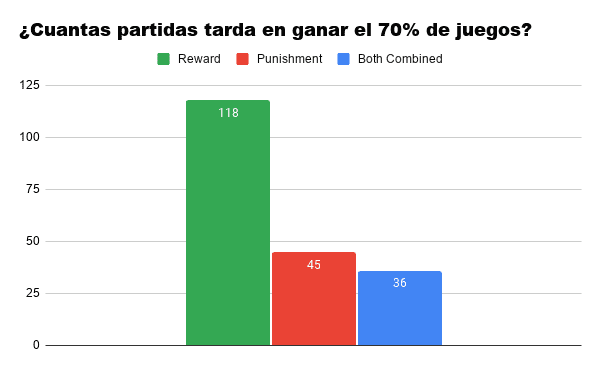
Como era de esperar, el algoritmo que combina ambos tiene un gran rendimiento a «edades» tempranas, alcanzando el rendimiento del 70% en tan solo 36 partidas, como media, mientras que el de Recompensa tarda bastante más en asentarse como un «buen jugador».
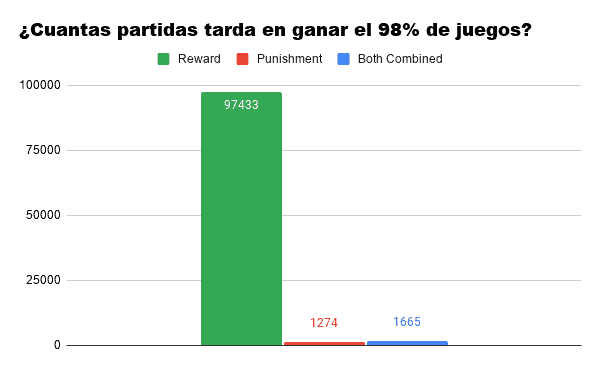
Si pasamos a hablar sobre lo que tarda cada algoritmo en alcanzar un rendimiento medio del 98% la gráfica se dispara. Nos encontramos con que nuestro algoritmo de Recompensa tiene serias dificultades en alcanzar el umbral, y esto se debe a que con cada victoria, aprende menos que con la anterior. (Una variante que al principio tiene un 50% de probabilidad de ganar luego tendrá un 66%, luego un 75%, 80%, 83%, 85%, etc…)
En cuanto a los otros dos algoritmos: aquí ya podemos apreciar cómo el de Castigo tarda unas 400 partidas menos que la combinación de ambos en alcanzar un umbral casi perfecto. Aún así, simular 400 partidas de este mini-juego es casi instántaneo y puede ser que para ciertas funciones el azul pueda ser más práctico.
Conclusión Castigo vs Recompensa:
No llego a comprender en qué casos sería conveniente utilizar Recompensas (lo siento, no sé demasiado sobre Machine Learning) pero podemos apreciar que en este tipo de entrenamientos lo más conveniente es eliminar cuanto antes las conductas negativas puesto que nos interesa terminar la fase de aprendiaje lo más rápido posible para posteriormente pasar a utilizar los comportamientos positivos restantes.
Puedes encontrar el código Java de este algoritmo en mi repositorio público de GitHub: https://github.com/ZaneDario/Hexapawn_Punishment_vs_Reward

Deja una respuesta